Retrieval-Augmented Generation (RAG): Smarter AI with Real Knowledge
Large Language Models are powerful. But they have a weakness:
They generate responses based on training data, not real-time knowledge.
That’s where RAG (Retrieval-Augmented Generation) changes the game.
RAG combines language models with external data retrieval. Instead of guessing from memory, the model first searches for relevant information — then generates a response based on that data.
This makes AI more accurate, reliable, and context-aware.
What is RAG?
Retrieval-Augmented Generation (RAG) is an AI architecture that:
Retrieves relevant information from a knowledge base
Feeds that information into a language model
Generates a response grounded in retrieved data
In simple terms:
Search first → Generate later
This reduces hallucination and improves factual correctness.
Why Traditional LLMs Have Limitations
Standard language models:
Are trained on fixed datasets
Cannot access real-time private databases
May generate incorrect but confident answers
They predict the next word statistically.
They do not “verify” facts.
RAG adds verification through retrieval.
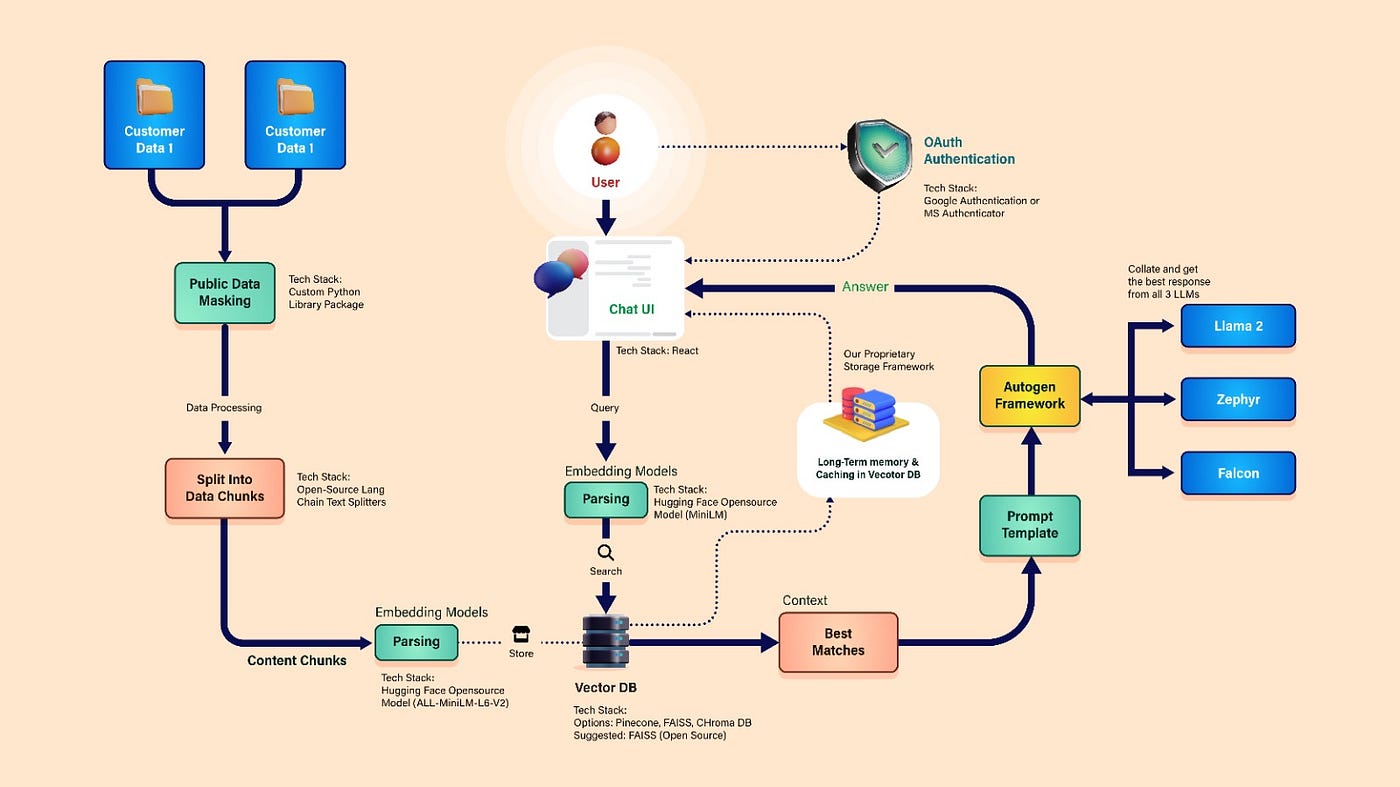
How RAG Works


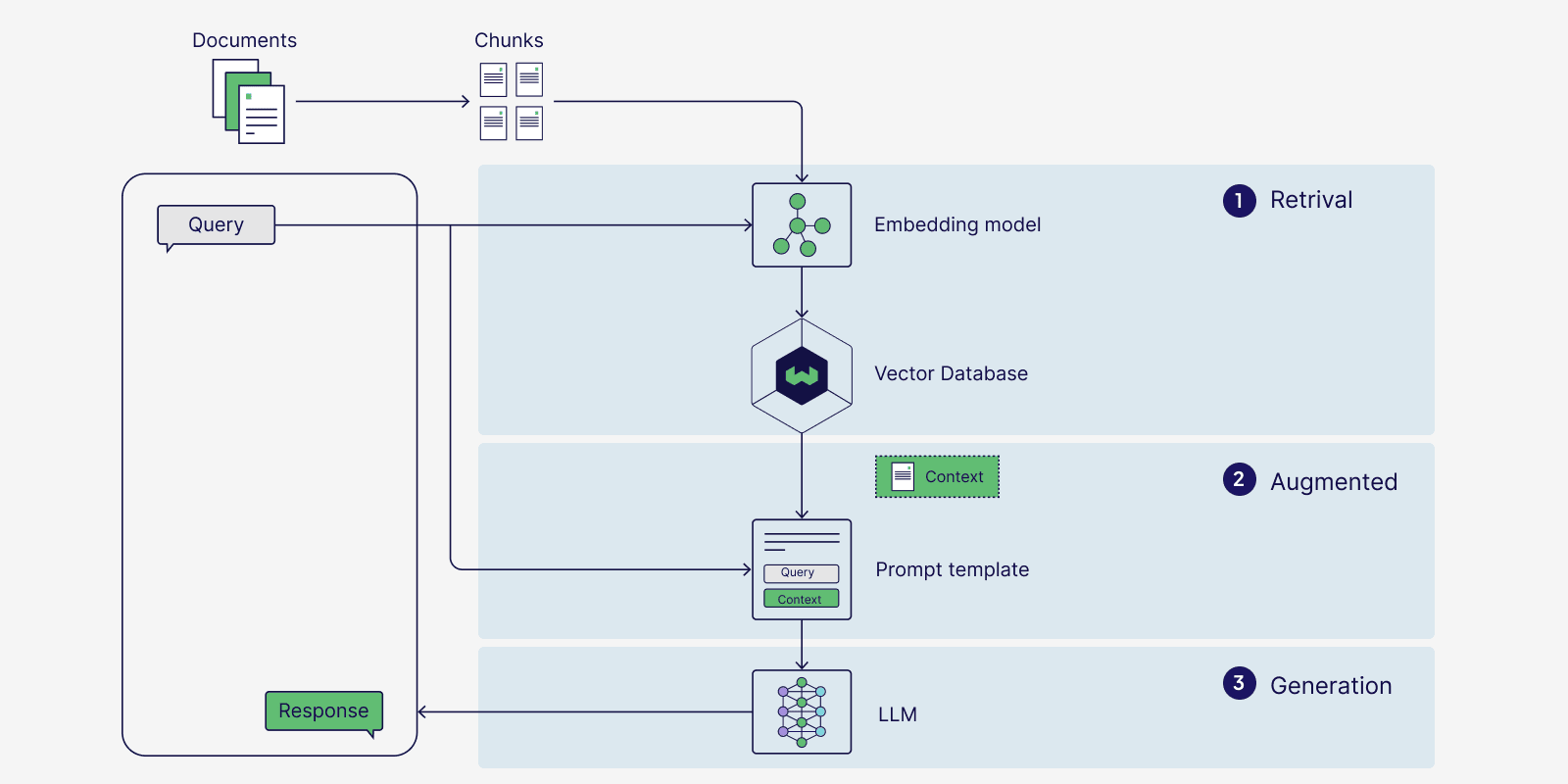
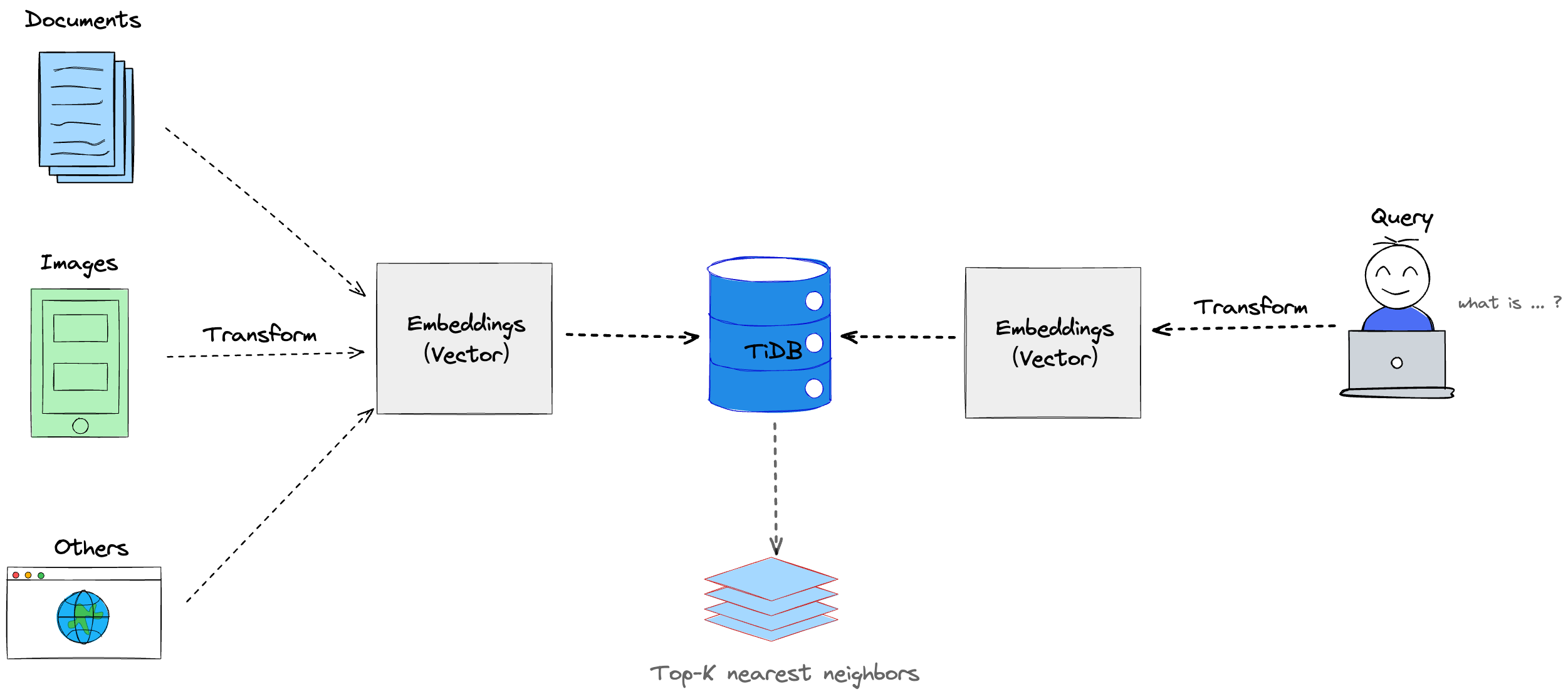
Step-by-Step Workflow
User Query
A question is asked.Embedding Creation
The query is converted into a numerical vector.Vector Search
The system searches a vector database for similar documents.Context Injection
Relevant documents are passed to the language model.Response Generation
The model generates an answer based on retrieved context.
This architecture makes responses data-driven.
Core Components of RAG
A RAG system typically includes:
Large Language Model (LLM)
Embedding model
Vector database
Document store
Retrieval mechanism
If retrieval fails, generation quality drops.
The system is only as good as its data pipeline.
Real-World Applications of RAG
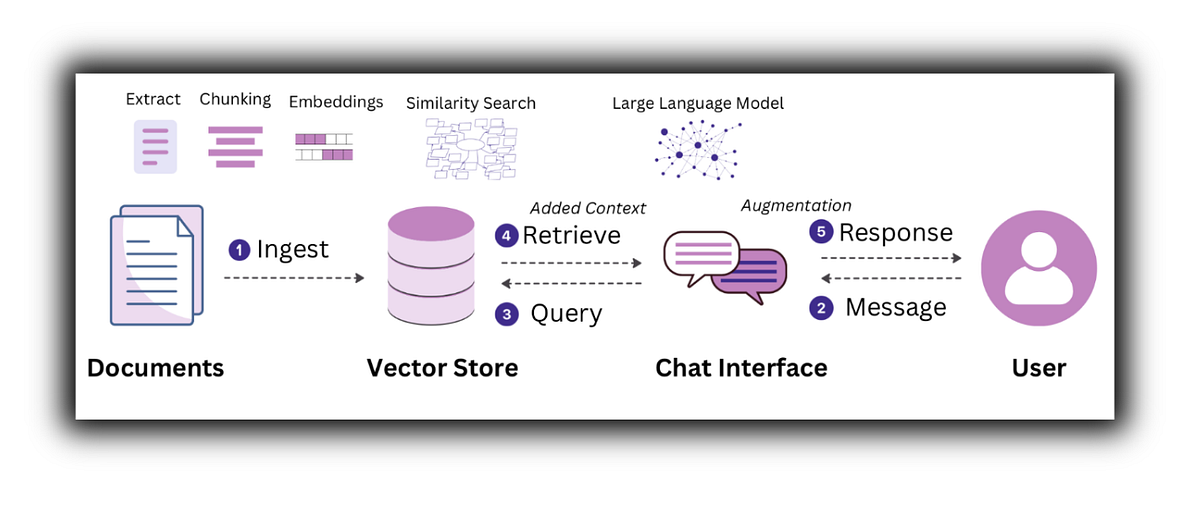
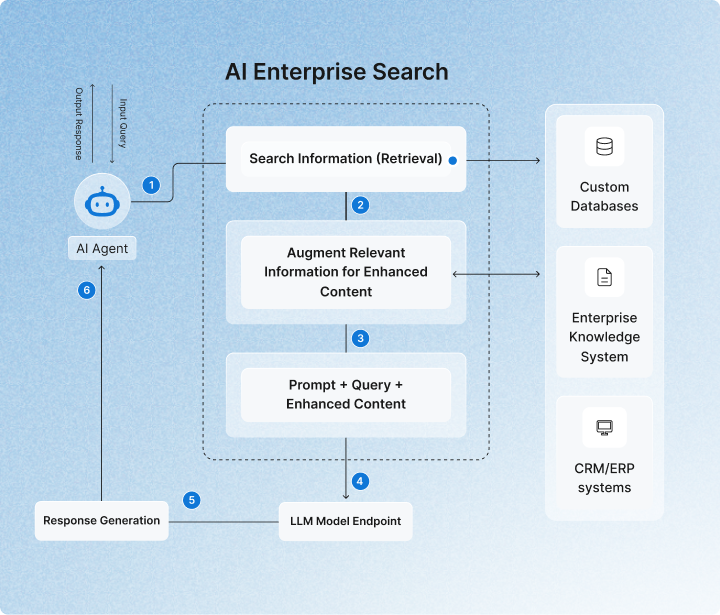

1. Enterprise Chatbots
Companies connect AI to internal documents.
Instead of generic responses, the bot answers using company-specific data.
2. Legal & Compliance Systems
RAG retrieves relevant laws or case documents before generating legal explanations.
Accuracy is critical in these domains.
3. Customer Support Automation
AI searches FAQs and manuals before responding.
This reduces hallucination and improves consistency.
4. Research Assistance
RAG can search academic papers before generating summaries.
It bridges generative AI with structured knowledge.
Advantages of RAG
Reduces hallucinations
Provides up-to-date information
Works with private databases
Improves factual grounding
More transparent than pure LLM
RAG turns generative AI into knowledge-based AI.
Challenges of RAG
Be realistic. It is not perfect.
Requires proper document indexing
Vector search tuning is complex
Poor data quality = poor results
Latency increases due to retrieval step
Without strong data engineering, RAG fails.
RAG vs Fine-Tuning
Understand the difference:
| RAG | Fine-Tuning |
|---|---|
| Retrieves external data | Modifies model weights |
| Works with dynamic data | Works with static training |
| Easier to update knowledge | Requires retraining |
| Better for enterprise search | Better for behavior control |
For most business applications, RAG is more scalable.
Future of RAG
RAG will evolve with:
Hybrid search (keyword + vector search)
Real-time streaming databases
Multi-modal retrieval (text + image + audio)
Agent-based AI systems
The future of reliable AI systems depends on grounding generation in verified data.
Pure generation is powerful.
Grounded generation is dependable.
Conclusion
Retrieval-Augmented Generation is not just a trend. It is a structural improvement in AI architecture.
It addresses the biggest weakness of large language models: lack of real-time knowledge grounding.
If you want to build production-grade AI systems, learn:
Embeddings
Vector databases
Information retrieval
Prompt engineering
System architecture
RAG is where AI moves from impressive to trustworthy.
